Capítulo 4 Manipulando e analisando data frames
Agora que já conhecemos todos os tipos de objetos no R, vamos começar a trabalhar com bancos de dados. Aqui iremos trabalhar com os dados dos passageiros do Titanic que estão disponíveis no pacote Stat2Data. Então, a primeira coisa que precisamos fazer é instalar o pacote via comando install.packages("Stat2Data"). Após a instalação precisamos chamar o pacote e depois precisamos baixar o banco que iremos utilizar:
A primeira coisa que fazemos quando abrimos um banco de dados novo é ver como ele está organizado, quais são suas variavei e se ele tem muitos erros. Para isso é útil utilizarmos as funções head() e tail(). Como padrão elas mostram as seis primeiras e seis últimas linhas do banco. Caso, desejem que o R mostre mais itens é possível utilizar o argumento n = dentro da função e inserir o número desejado.
Depois de vermos como está o começo (head) e o final (tail) do nosso banco, utilizamos duas outras funções que nos mostrarão como está estruturado o banco e um resumo de como estão as variáveis.
## 'data.frame': 1313 obs. of 6 variables:
## $ Name : Factor w/ 1310 levels "Abbing, Mr Anthony",..: 22 25 26 27 24 31 45 46 50 54 ...
## $ PClass : Factor w/ 4 levels "*","1st","2nd",..: 2 2 2 2 2 2 2 2 2 2 ...
## $ Age : num 29 2 30 25 0.92 47 63 39 58 71 ...
## $ Sex : Factor w/ 2 levels "female","male": 1 1 2 1 2 2 1 2 1 2 ...
## $ Survived: int 1 0 0 0 1 1 1 0 1 0 ...
## $ SexCode : int 1 1 0 1 0 0 1 0 1 0 ...A função str(), de structure nos mostra a estrutura do nosso banco. Aqui já conseguimos ver que temos seis variáveis e as classes de cada uma delas. Já conseguimos identificar alguns problemas no nosso banco. Você consegue identificá-los?
## Name PClass Age Sex
## Carlsson, Mr Frans Olof : 2 * : 1 Min. : 0.17 female:462
## Connolly, Miss Kate : 2 1st:322 1st Qu.:21.00 male :851
## Kelly, Mr James : 2 2nd:279 Median :28.00
## Abbing, Mr Anthony : 1 3rd:711 Mean :30.40
## Abbott, Master Eugene Joseph: 1 3rd Qu.:39.00
## Abbott, Mr Rossmore Edward : 1 Max. :71.00
## (Other) :1304 NA's :557
## Survived SexCode
## Min. :0.0000 Min. :0.0000
## 1st Qu.:0.0000 1st Qu.:0.0000
## Median :0.0000 Median :0.0000
## Mean :0.3427 Mean :0.3519
## 3rd Qu.:1.0000 3rd Qu.:1.0000
## Max. :1.0000 Max. :1.0000
## A função summary(), mostra um resumo das nossas variáveis. Conseguimos identificar outros problemas no nosso banco. Quais?
Cada banco de dados terá erros e problemas diferentes. Aqui, iremos trabalhar alguns desses possíveis erros como exemplo.
4.1 Arrumando o banco de dados
Podemos identificar os seguintes problemas no banco Titanic:
1 - A variável Name está sendo lida pelo R como um factor enquanto deveria estar sendo lida como um char
2 - A variável PClass tem um elemento atribuído como * sendo lido como um dos fatores, precisamos transformá-lo em NA
3 - A variável Age tem valores menores do que 1 com decimais. é melhor transformar esses valores em 0
4 - As variáveis Survived e SexCode estão sendo lidas como numeric, precisamos lê-las como factor
Vamos resolver cada um dos problemas a seguir.
Primeiro, transformamos as variáveis que precisam ser transformadas em outras classes. Para mudar a classe de uma variável utilizamos as funções da família as.classe() (onde “classe” é a classe para qual queremos transformar). A seguir transformamos a variável Name em char substituindo a coluna original:
Quando fazemos a alteração da variável do modo acima estamos substituindo a coluna original. Caso isso não seja o desejado é necessário mudar o nome da coluna na atribuição. Se a coluna não existir o R irá criar uma coluna nova com esse nome.
E transformamos as variáveis Survived e SexCode em factor:
Agora vamos resolver o problema com a variável PClass. Para descobrirmos qual elemento tem o valor * precisamos utilizar a função which() da seguinte forma:
## [1] 457Agora sabemos que o elemento 457 armazena na variável PClass o elemento *.
Vamos dar uma olhada no elemento 457 inteiro?
## Name PClass Age Sex Survived SexCode
## 457 Jacobsohn Mr Samuel * NA male 0 0Para substituir o valor dentro da PClass utilizamos o seguinte comando:
Vamos verificar novamente o elemento 457:
## Name PClass Age Sex Survived SexCode
## 457 Jacobsohn Mr Samuel <NA> NA male 0 0Fizemos a substituição, mas se pedirmos novamente o resumo das variáveis veremos que o factor * ainda estará lá, ainda que nos informe que nenhum caso corresponde a esse factor:
## Name PClass Age Sex Survived SexCode
## Length:1313 * : 0 Min. : 0.17 female:462 0:863 0:851
## Class :character 1st :322 1st Qu.:21.00 male :851 1:450 1:462
## Mode :character 2nd :279 Median :28.00
## 3rd :711 Mean :30.40
## NA's: 1 3rd Qu.:39.00
## Max. :71.00
## NA's :557Precisamos atualizar os fatores da PClass:
Agora sim:
## Name PClass Age Sex Survived SexCode
## Length:1313 1st :322 Min. : 0.17 female:462 0:863 0:851
## Class :character 2nd :279 1st Qu.:21.00 male :851 1:450 1:462
## Mode :character 3rd :711 Median :28.00
## NA's: 1 Mean :30.40
## 3rd Qu.:39.00
## Max. :71.00
## NA's :557Bom, agora só falta arrumarmos a variável idade.
Primeiro vamos descobrir quais elementos tem o valor menor do que 1:
## [1] 5 359 545 617 752 764Seria bom se também pudéssemos dar uma olhadas nesses elementos, já que não são tantos. Lembram da função subset()?
## Name PClass Age Sex Survived SexCode
## 5 Allison, Master Hudson Trevor 1st 0.92 male 1 0
## 359 Caldwell, Master Alden Gates 2nd 0.83 male 1 0
## 545 Richards, Master George Sidney 2nd 0.80 male 1 0
## 617 Aks, Master Philip 3rd 0.83 male 1 0
## 752 Danbom, Master Gilbert Sigvard Emanuel 3rd 0.33 male 0 0
## 764 Dean, Miss Elizabeth Gladys (Millvena) 3rd 0.17 female 1 1Vamos utilizar a mesma lógica da substituição de PClass para substituir as idades menores que 1 por 0:
Agora que arrumamos tudo que precisavamos arrumar no banco, vamos dar uma olhada no nosso banco:
## Name PClass Age Sex Survived SexCode
## Length:1313 1st :322 Min. : 0.00 female:462 0:863 0:851
## Class :character 2nd :279 1st Qu.:21.00 male :851 1:450 1:462
## Mode :character 3rd :711 Median :28.00
## NA's: 1 Mean :30.39
## 3rd Qu.:39.00
## Max. :71.00
## NA's :5574.2 Criando variáveis novas
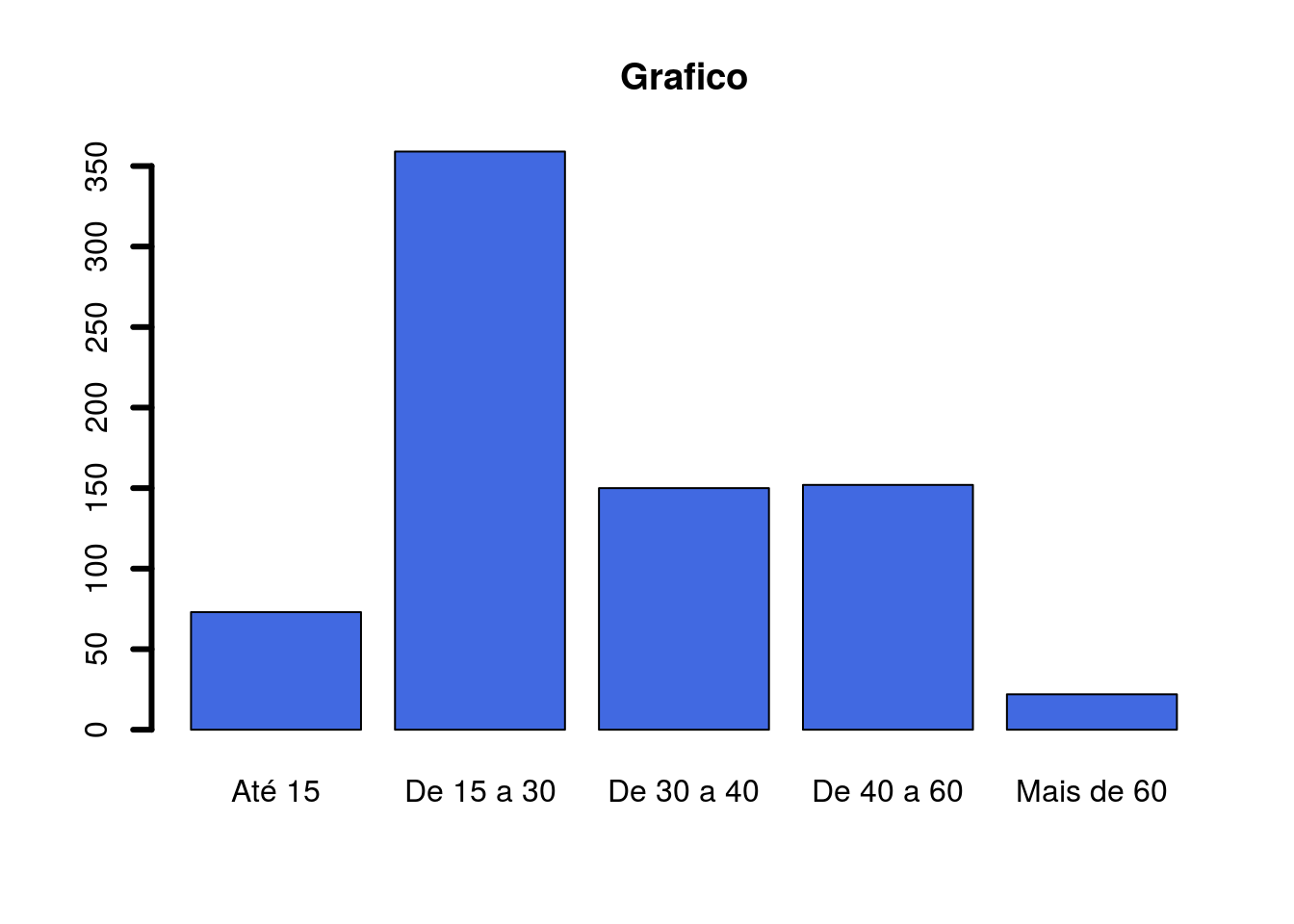
Podemos criar uma variável nova transformando a variável Age em categorias. Para isso precisamos utilizar a função cut(). Iremos cortar a nossa variável em 5 categorias: até 15 anos, de 15 a 30 anos, de 30 a 40 anos, de 40 a 60 anos e mais de 60 anos. Precisamos identificar no argumento breaks os limites do intervalos desejados a partir de um vetor ou inserir o número de intervalos (nesse caso a função irá definir os cortes, depois será necessário mudar os nomes dos cortes). Para criar uma variável nova precisamos atribuir a função em uma coluna do banco Titanic que ainda não existe (o R irá criá-la com a atribuição desejada):
Titanic$AgeCat <- cut(Titanic$Age,
breaks = c(-Inf,15,30,40,60,75),
labels = c("Até 15", "De 15 a 30",
"De 30 a 40", "De 40 a 60", "Mais de 60"))Vamos dar uma olhada no nosso banco:
## Name PClass Age Sex Survived SexCode
## Length:1313 1st :322 Min. : 0.00 female:462 0:863 0:851
## Class :character 2nd :279 1st Qu.:21.00 male :851 1:450 1:462
## Mode :character 3rd :711 Median :28.00
## NA's: 1 Mean :30.39
## 3rd Qu.:39.00
## Max. :71.00
## NA's :557
## AgeCat
## Até 15 : 73
## De 15 a 30:359
## De 30 a 40:150
## De 40 a 60:152
## Mais de 60: 22
## NA's :557
## Caso precise remover alguma coluna do banco utilize a seguinte lógica:
banco <- banco[,-x]onde o x é o número da coluna que queremos excluir. Se quiser excluir mais de uma coluna utilize-c(x, y, z)(para colunas separadas) ou-[x:y](para intervalos de coluna)
##Tabelas de frequência e de contigência
Algo muito comum nas primeiras análises com bancos de dados são as tabelas de frequências. Com elas podemos ver como estão distribuídos nossos dados. A função table() retorna a frequência absoluta da variável desejada:
##
## 1st 2nd 3rd
## 322 279 711Se quisermos saber a frequência relativa utilizamos a função prop.table() junto com a função anterior (ou atribuímos a função table() a uma variável e depois utilizamos prop.table() nessa variável).
##
## 1st 2nd 3rd
## 0.2454268 0.2126524 0.5419207Outra tabela importante é a tabela de contigência (ou tabela cruzada), em que queremos ver a frequência das ocorrências dos cruzamentos das varia’veis, considerando suas categorias. As funções table() e ftable() retornam as tabelas de contingência em uma matriz. Para o cruzamento de duas variáveis o resultado da utilização das duas funções são bem parecidas:
##
## female male
## 1st 143 179
## 2nd 107 172
## 3rd 212 499## female male
##
## 1st 143 179
## 2nd 107 172
## 3rd 212 499Porém, quando queremos cruzar mais de duas variáveis vemos diferenças relevantes entre os resultados das funções:
## , , = 0
##
##
## female male
## 1st 9 120
## 2nd 13 147
## 3rd 132 441
##
## , , = 1
##
##
## female male
## 1st 134 59
## 2nd 94 25
## 3rd 80 58A função table() separa a última variável inserida e mostra as tabelas cruzadas com as outras variáveis para cada uma das categorias da variável três. De forma diferente, a função ftable() retorna uma tabela organizada com as três variáveis:
## 0 1
##
## 1st female 9 134
## male 120 59
## 2nd female 13 94
## male 147 25
## 3rd female 132 80
## male 441 58Ainda, podemos utilizar a função ftable() com a função xtabs() para termos uma tabela de contingência com os nomes corretos das variáveis.
## Survived 0 1
## PClass Sex
## 1st female 9 134
## male 120 59
## 2nd female 13 94
## male 147 25
## 3rd female 132 80
## male 441 58Agora, se queremos ver a as tabelas de contingências com os valores relativos das frequências precisamos utilizar as funções ftable() e prop.table() conjuntamente, mas adicionamos um 1 para o percentual na linha e um 2 para o percentual na coluna:
## 0 1
##
## female 33.33333 66.66667
## male 83.31375 16.68625## 0 1
##
## female 17.84473 68.44444
## male 82.15527 31.55556Novamente, table() e ftable() funcionam da mesma forma quando tratamos de duas variáveis, mas quando estamos trabalhando com mais de duas variáveis ftable() retorna uma tabela mais organizada:
## 1st 2nd 3rd
##
## female 0 5.844156 8.441558 85.714286
## 1 43.506494 30.519481 25.974026
## male 0 16.949153 20.762712 62.288136
## 1 41.549296 17.605634 40.845070Agora, com a tabela class_sex que criamos anteriormente podemos fazer testes de independência utilizando as funções chisq.test() e fisher.test(), por exemplo. A função summary() também pode ser utilizada para o teste do chi-quadrado:
## Number of cases in table: 1312
## Number of factors: 2
## Test for independence of all factors:
## Chisq = 22.217, df = 2, p-value = 1.499e-054.3 Gráficos base do R
Agora veremos rapidamente a construção de alguns gráficos do pacote base do R e algumas das personalizações possíveis. Iremos ver no capítulo {#ggplot} como fazer gráficos com o pacote ggplot2, mas por ora os gráficos base serão suficientes.
No geral, todas as personalizações apresentadas nos gráficos são possíveis de serem feitas nos outros gráficos, respeitando os limites de cada tipo de gráficos. Há uma infinidade de adaptações possíveis para cada gráfico, para saber como realizá-las leia a documentação referente a cada função de gráfico no
helpou procure tutoriais e documentações na internet.
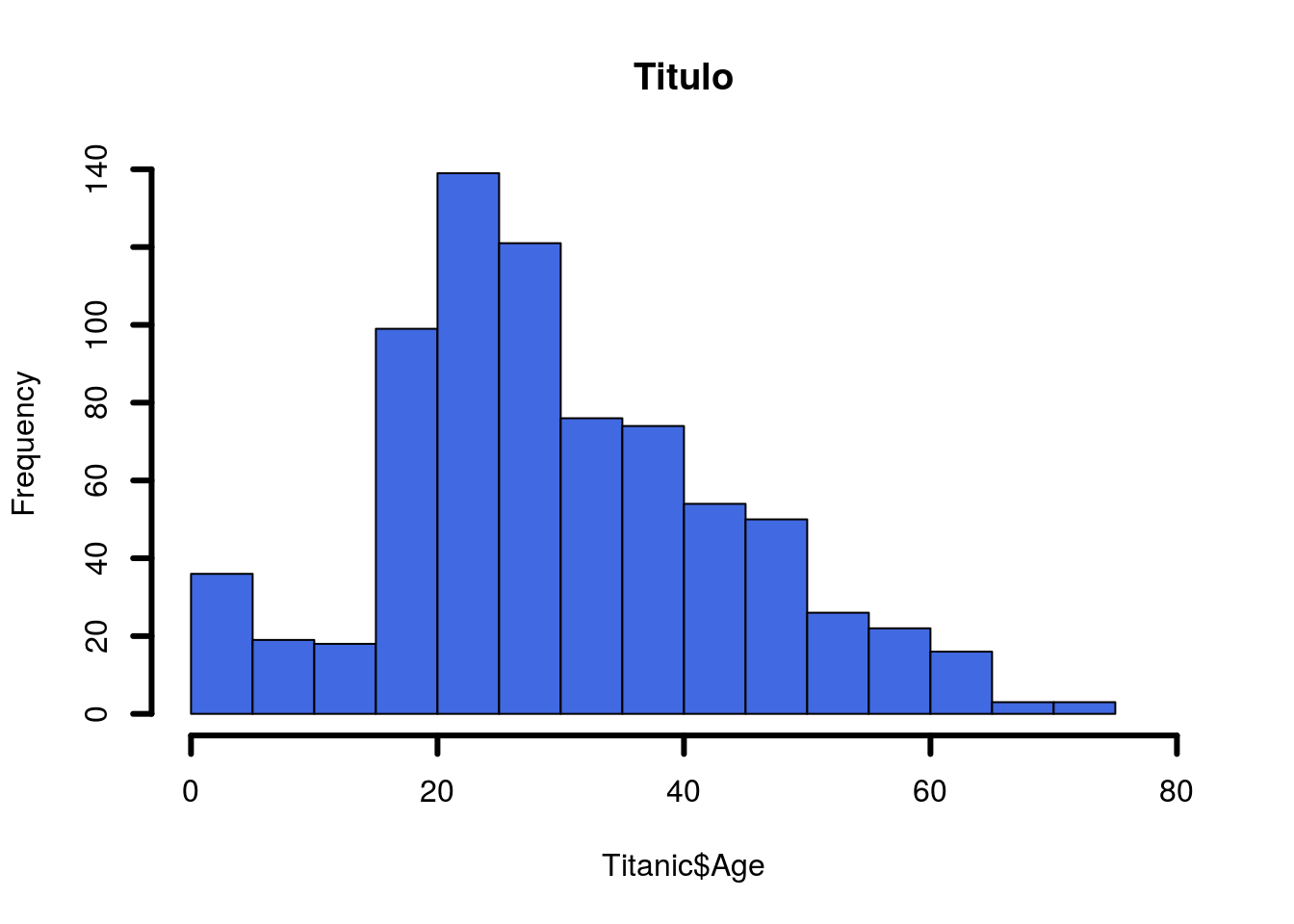
Para gerar histogramas utilizamos a função hist(), podemos delimitar a extensão dos eixos x e y com os argumentos xlim e ylim, dentro precisamos colocar um vetor com os limites desejados. Para adicionar um título para os gráficos definimos o argumento main. Ainda podemos definir a cor e espessura das linhas dos eixos com col e lwd:
Para as variáveis categóricas geramos gráficos de barras com a função barplot() a partir da tabela de frequências da variável:
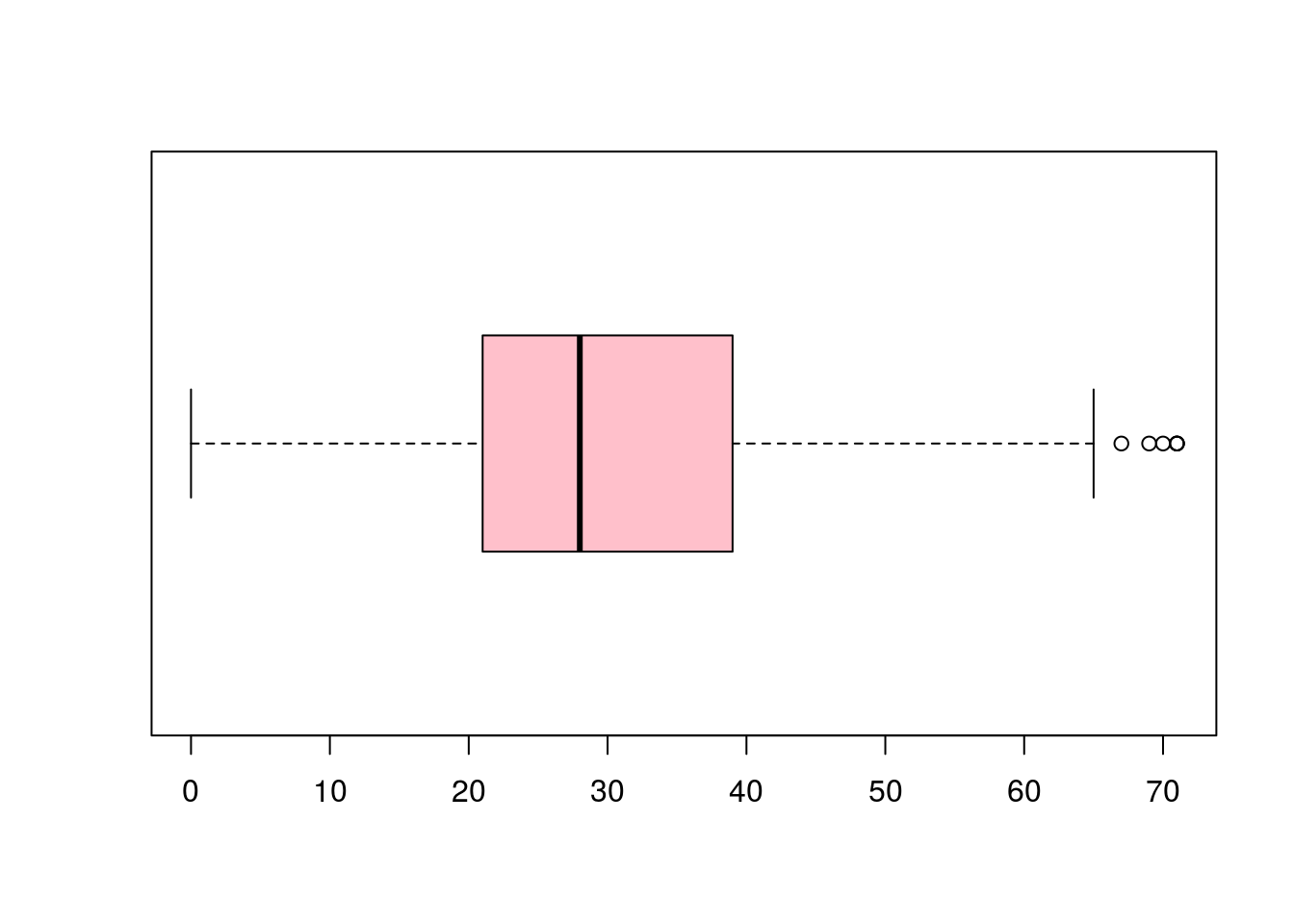
A função boxplot() possibilita a criação de boxplots. Podemos rotacionar os gráficos com o argumento horizontal = TRUE:
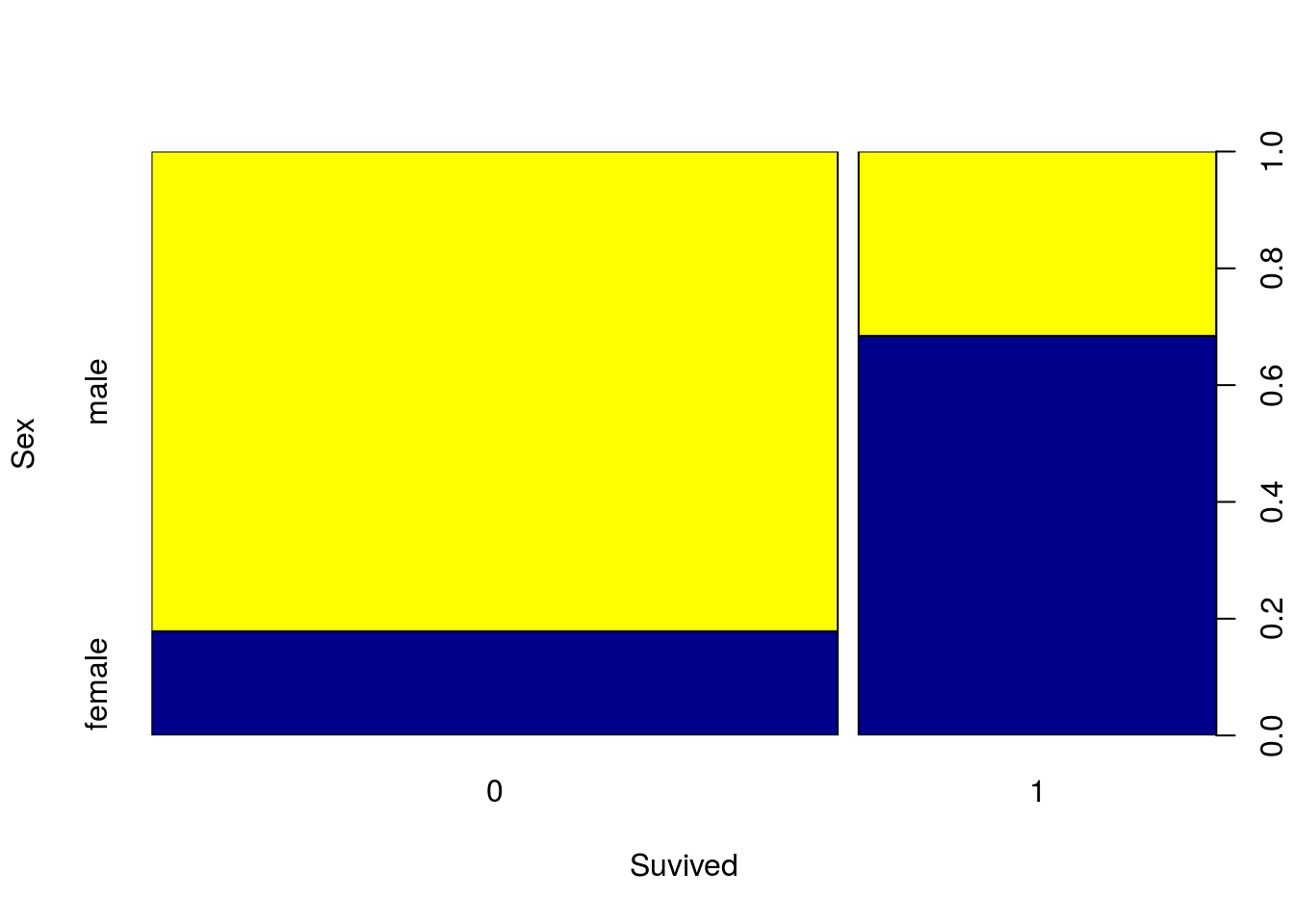
Podemos também realizar gráficos com duas variáveis categóricas combinadas. Com os argumentos xlab e ylab adicionamos os nomes dos eixos x e y:
A partir da frequência da variável PClass que atribuímos anteriormente podemos realizar um gráfico de pizza, com a função pie():
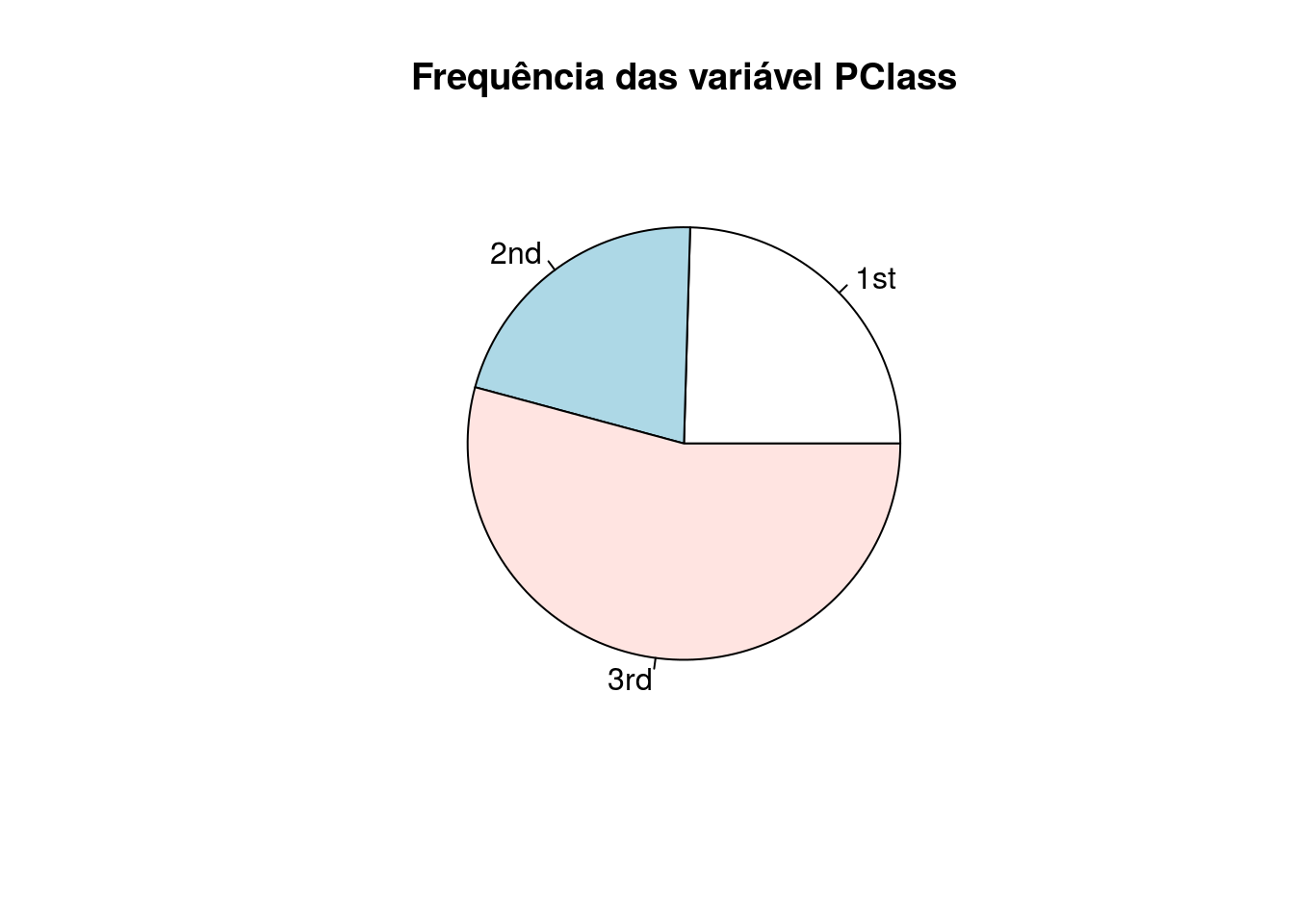
A partir da tabela de contigência das variáveis Sex e Survived podemos criar o gráfico de barras empilhadas. Adicionamos ainda a função legend() para adicionar a legenda das cores da variável Sex. Com o argumento da legenda horiz = TRUE dizemos que queremos que a legenda esteja na horizontal (uma categoria ao lado da outra), o argumento pch informa o código do símbolo que desejamos utilizar na legenda12, inset informa onde queremos colocar a legenda em relação a margem e bty como queremos a caixa da legenda (no caso deixamos a caixa sem borda e sem preenchimento). Ainda, a localização da legenda pode ser: bottomright, bottom, bottomleft, left, topleft, top, topright, right ou center.
barplot(table(Titanic$Sex, Titanic$Survived), ylim = c(0,1000), xlab = "Survived", main = "Distribuição", col=c("darkblue", "red"))
legend("top", c("Female", "Male"), horiz = TRUE, col = c("darkblue", "red"), pch = 16, inset = c(0,0), bty = "n")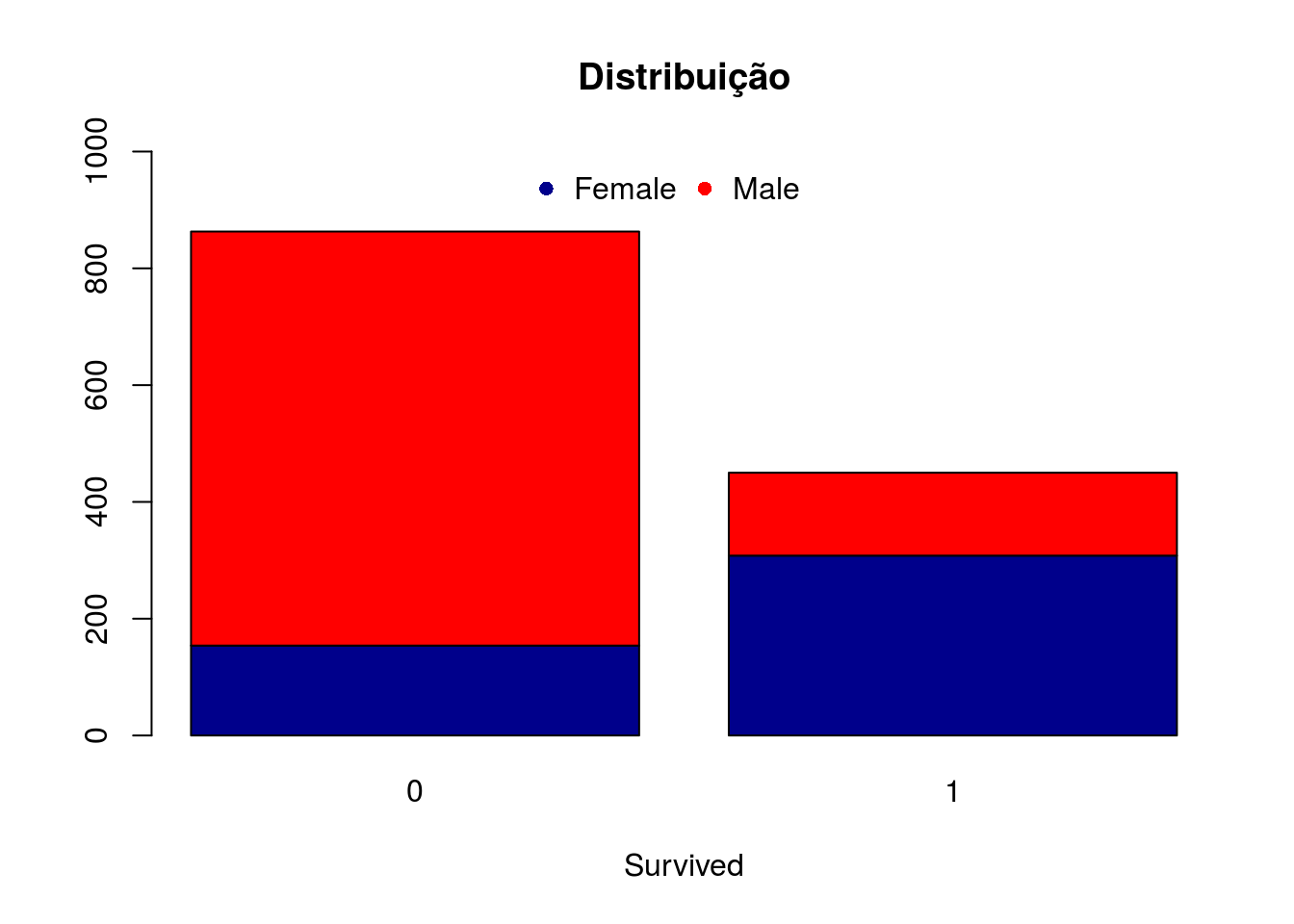
Por fim, podemos combinar diversos gráfico em uma mesma imagem. Para isso precisamos primeiro utilizar a função par, com o argumento mfrow informando a quantidade de linhas e colunas que queremos adicionar na nossa imagem. Aqui utilizaremos 1 linha com 2 colunas pois queremos 2 gráficos um do lado do outro. E o argumento oma informa o tamanho das margens externas da figura na ordem inferior, esquerda, superior e direita. Depois, nas linhas abaixo inserimos os gráficos desejados:
par(mfrow = c(1,2), oma = c(1,1,1,1))
plot(Titanic$Survived, Titanic$Sex, col = c("Dark Blue", "Yellow"))
plot(Titanic$Survived, Titanic$PClass, col = c("Gray", "Dark Blue", "Red"))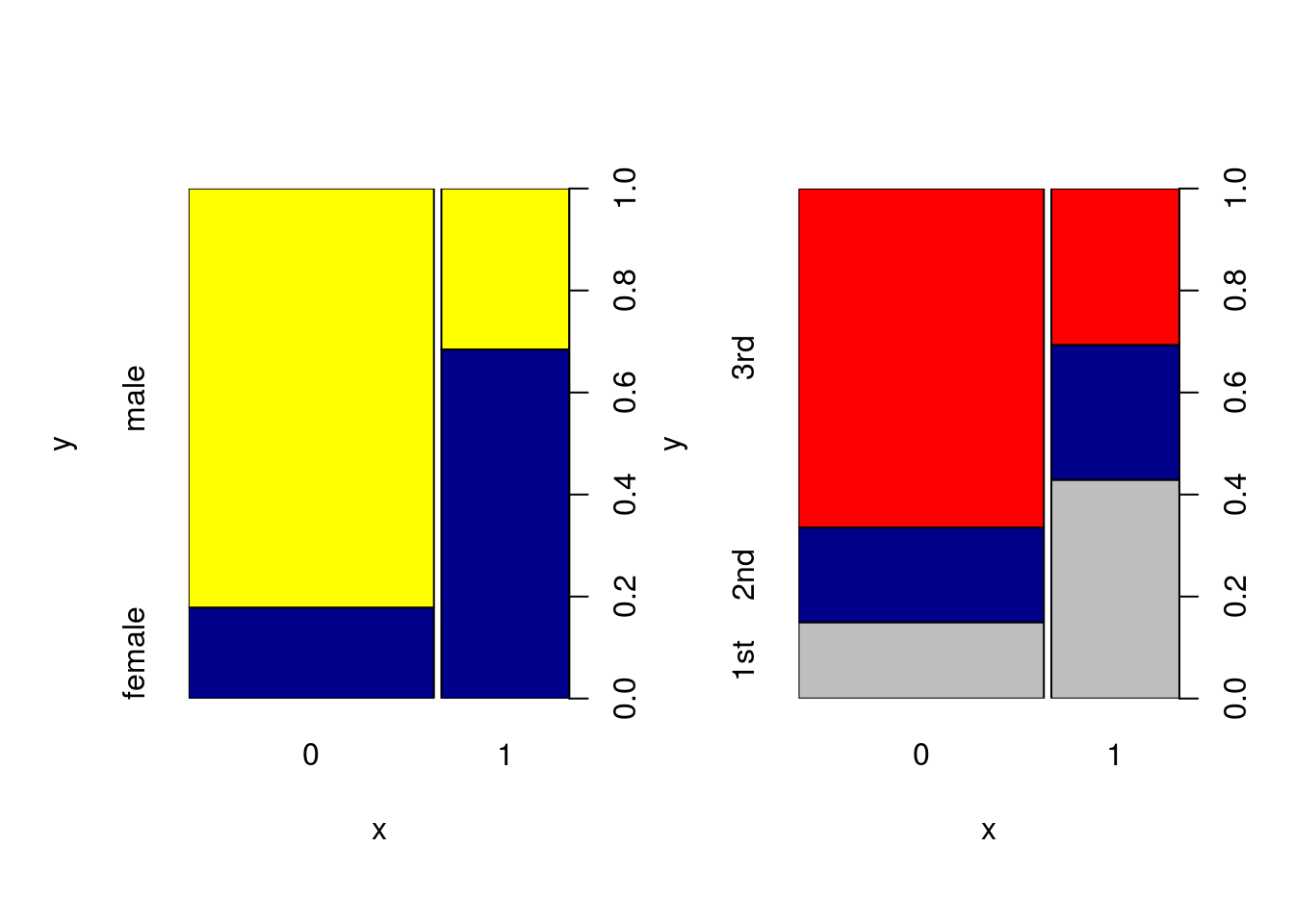
4.4 Importação e exportação de bancos de dados
Os bancos de dados disponibilizados no R são muito úteis mas também precisamos importar nossos bancos de dados para análise. O R possui diversas funcionalidades para importação dos mais diversos tipos de bancos de dados (.csv, .xlsx, .sav, etc). Aqui iremos ver como importar e exportar bancos .csv.
Para tanto precisamos utilizar as funções read.csv() para importar e write.csv() para exportar. O formato padrão de importação é:
read.csv(“nomebanco.csv”, na.strings = "“, stringsAsFactors = FALSE, header = TRUE, encoding =”UTF-8")
Onde,
nomebancoé o nome do arquivo que você deseja importar. Se o arquivo não está no diretório raiz do seu projeto, é necessário colocar todo o endereço (Atenção que no Windows é necessário inverter as barras do endereço). é necessário a extensão do arquivo.na.stringsé a indicação para o R de qual string ele deve ler como NA. Se você não sabe como está configurado o seu banco utilize "" neste argumento. Assim o R irá ler apenas os locais em branco como NAheaderé a indicação de que o seu banco tem um cabeçalho. Assim, o R irá ler a primeira linha como nome das colunas. Se o seu banco não tem cabeçalho atribuaFALSEa esse argumentoencodingé a indicação da codificação do seu banco. Geralmente no Brasil utilizamos oUTF-8
Atenção! Se o seu banco está comfigurado com
,como padrão de separação para decimais dos números é necessário utilizar a funçãoread.csv2()
Para exportar um banco já trabalhado no R utilize o seguinte comando:
write.csv(banco, file = “nomearquivo.csv”, na = “NA”)
Onde,
bancoé o nome do banco no R que você deseja exportarfileé o nome do arquivo que você deseja criar. Será salvo automaticamente na pasta raiz do seu projeto a não ser que você indique um outro endereço. é necessário a extensão do arquivo.naé a indicação de como estão os NAs no seu banco.
Atenção! Se você deseja que seu banco seja salvo no padrão de seperação de decimais com
,é necessário utilizar a funçãowrite.csv2()
Add Points to a Plot: https://www.rdocumentation.org/packages/graphics/versions/3.6.1/topics/points↩︎